Disambiguating Persons
There are many reasons to track, and disambiguate, natural persons in the world of compliance as Code. Natural persons (a human being as distinguished from a person as a corporation created by operation of law), heretofore referred to simply as “persons”, fall into two categories: contributors and targets of compliance.
Who is the audience for this topic?
If you are dealing with either GRC or SecOps tools you are the audience for this topic. Because more than likely, you and your fellow compatriots are both contributors to your projects as well as targets of compliance.
Contributors
Every organization that has a documented schema in the realm of a Common Data Format (listed HERE) identifies various forms of contributors to their content. These contributors are listed as anything from primary authors, through editors, through “commentators” of contributed content to their various repositories of information. We will this collective group contributors.
In addition, many frameworks, such as HITRUST, SCF, and others, don’t present who contributed to the content. As of this writing there is no possibility for adjudicating the veracity of how the mapping was done within those frameworks, the quality of the mapping, or even the research behind the mapping. This renders any mapping without the documented contributors (and the facts behind the mapping) non-satis probandi (no evidence).
Contributors to these systems must be tracked; for accountability of content, for accolades as contributors, for any number or reasons.
Targets of Compliance
People aren’t just contributors. We are also the target of compliance. People who
- are assigned to follow compliance documents;
- are given permission to use systems;
- are given access to physical locations and assets;
- have taken actions that must be logged;
- etc.
Thus, “Ed” or “Eunice” in real-life must be directly linked to “Ed” or “Eunice” in a system’s permission structure, or who signed the HR policy, or who walked through the front door’s sentry system.
Before we discuss the schema, we must first discuss disambiguating a person from an agent, or another person.
Key terms we need to be aligned with
Juliet (yes Shakespeare’s Juliet) argued that “a rose by any other name would smell as sweet,” arguing that Romeo Montague’s name shouldn’t be the problem (“'Tis but thy name that is my enemy; Thou art thyself, though not a Montague” she followed up). The problem for both Romeo and Juliet was that his name did cause a problem – and got them both killed. So, what’s in a name? What do we need to know about names as key terms? A lot. Let’s start with the simple ones and go from there.
Persons
There are a bunch of terms that describe a person, with over 60 Common Controls focused on these terms:
- human: relating to a person.
- human being: any living or extinct member of the family Hominidae.
- identifiable person: one who can be identified, directly or indirectly, by one or more factors.
- individual: the person about whom the personal information is being collected.
- natural person: a living human being.
- person: a human individual.
- user: what they call a person in an organization or who consumes software or other services.
Linking natural people to identifiers
To link natural people to computer systems, we create representations of their names in various forms, with over 40 Common Controls focused on the following terms:
- e-mail address: a unique identifier in the form user-ID@domain-name that specifies a virtual location to which a message can be sent.
- organization-provided identifier: a unique user identifier that is issued to an information system user or network user by the organization.
- user identifier: a unique identifier (character string) assigned to each authorized computer user.
- username (and its variants, such as sign-in name, login name, etc.): A person’s identification on a computer system, network, or online service.
- electronic identification name: a unique number that is stored on a microchip and is detectable by radio frequency scanners or transponders.
- display name: an identifier that is visible to other users and message recipients.
- user account alias: an alternate account that points to the user account but uses a created alternate name for accessing the user account.
- user account: information that tells a computer which files and folders to access for a specific user, which personal preferences to have in place, and what can be accessed by the user.
Then there’s how persons’ names are tackled
If some type of identifier links to a person, the person’s name is used to create that identifier. Here are the various terms we’ve found within the world of compliance that deal specifically with the parts of a person’s name. There are well over 100 Common Controls focused on the terms below:
- name: the word or phrase by which an individual, family, organization, or thing is known or referred to.
- full name: a person's whole name, including any prefixes (Dr. etc.), first name, middle name, surname, and any suffixes (Jr., etc.).
- individual’s name: a combination of an individual's first name (or first initial) and last name.
- person’s name: the word or words by which a person is known.
- personal name: the word or phrase by which an individual is known and distinguished from others, especially the form used as a heading.
- first name:
- christian name: the first name given to Christians at birth or christening.
- given name: the name that precedes the surname.
- last name:
- family name: the name used to identify the members of a family (as distinguished from each member's given name).
- maiden name: a woman's surname before marriage.
- married name: a person's surname, or last name, acquired through marriage.
- surname: a hereditary name common to all members of a family, as distinct from a given name.
- alias: a name that has been assumed temporarily.
- assumed name: a name that has been assumed temporarily.
- pseudonym: an assigned identity that is used to protect an individual's true identity.
Finally, there are groups of terms for identity management
There is a suite of terms you’ll need to understand regarding how people, as users of software and services, are identified and managed within our organizations' various information systems.
- federated identity: a federated identity in information technology is the means of linking a person’s electronic identity and attributes, stored across multiple distinct identity management systems.
- federated identity management: a process that allows for the conveyance of identity and authentication information across a set of networked systems.
- identity provider: the party that manages the subscriber’s primary authentication credentials and issues assertions derived from those credentials.
- service provider: a business that provides its customers with a service.
- single sign-on: an authentication process that permits a user to access the resources of multiple software systems with one set of login credentials.
- user agent: a user agent is any software that retrieves and presents Web content for end-users or is implemented using Web technologies. User agents include Web browsers, media players, and plug-ins that help in retrieving, rendering, and interacting with Web content.
Digital Disambiguation of persons
Now that we know real people can be both contributors to the compliance effort and targets of the compliance effort, we need to understand a few things about disambiguating people through their digital identities1. Let’s look at a few use cases from our company, Univest.VIP located in Canoga Falls.
The problem of the Smiths
Within Univest.VIP, even in the small town of Canoga Falls, they have two people named Joseph Smith – cousins. One goes by “Joe” and the other is more formal, only answering to “Joseph”. When Joe joined the company, Lily, the HR director, assigned him the email address jsmith@univest.vip. However, that caused a digital identity problem for Lily six months later when his cousin Joseph joined. He couldn’t also be jsmith@univest.vip. So they changed their email naming policy (causing much consternation with IT) and now there is joesmith@univest.vip and josephsmith@univest.vip.
Organizational email, because each address has to be unique, is one way to disambiguate the digital representation of people in an organization. While simple and elegant for the time that Joe is actively using joesmith@univest.vip, there’s nothing to stop the organization from assigning that address to some other Joe Smith after our Joe Smith has left the organization. Unless, of course, the naming convention was like those of email service providers wherein an address is never used twice.
Ed’s problem
Then there’s Ed Higgins. Ed is a prolific contributor to many compliance websites. Ed is also a frequent job changer. Before his email address was edhiggins@univest.vip, it was edward@conogabank.com, and edh@conagalib.gov when we worked at the library. We’ll call these “Univest Ed”, “Bank Ed”, and “Librarian Ed”. Librarian Ed is the author of 15 research documents. Bank Ed is the author of 10 banking best practice guides. And Univest Ed is the author of almost a dozen investment best practice guides.
Without a way to trace Ed’s past emails, and link them to his digital persona, he wouldn’t get credit for two thirds of his published contributions.
Then there’s Eunice
Before Eunice met and married Ed, when she first began working at Univest, she was Eunice Harper. For the first two years after marriage, she was Eunice Harper Higgins. Then in their third year of marriage, she changed it again, this time to Eunice Higgins. So what’s the problem?
She signed the employee handbook as Eunice Harper. The investment applications that Univest released the year she got married have her digital persona as Eunice Harper Higgins, as do the investment logs it creates. Her new computer (and new email address) have her digital persona as Eunice Higgins. There are various policies and standards she’s signed off on with all three of her names.
Persons versus agents
Then there’s the problem of disambiguating a person from an agent. As Dan Brickley and Libbey Miller, co-authors of the FOAF (Friend of a Friend) Project2 wrote, people as well as bots can have e-mail addresses, chat addresses, etc. Distinguishing a person from a bot can’t be done by just checking an email address. Therefore, personal identity disambiguation must begin with disambiguating people from things. Until one passes the Turing test, a computer, which manages bots and various software agents, will remain an antonym of person3. Therefore, throughout the rest of this discussion, we will use the following terms and definitions (the term is a linked item to the ComplianceDictionary.com’s entry for the term):
| Term | Definition |
|---|---|
| agent | A program acting on behalf of a person or organization. |
| bot | A robot; A piece of software designed to complete a minor but repetitive task automatically and on command. |
| natural person | A living human being. Legal systems can attach rights and duties to natural persons without their express consent. |
Because a bot is a type of agent, we will refer to all computerized processes that communicate, as agents.
Disambiguating a person from an agent
The world is inundated with fake accounts on social media platforms run by bots of various types and for various reasons. Merely having an e-mail address or social media address isn’t enough to disambiguate a person from an agent. A shibboleth of sorts is necessary to distinguish the two4.
In 2015 DARPA initiated a Twitter Bot challenge to determine person or agent5. At that time, they came up with five criteria (user profile, syntax, semantics, behavior, network features) to disambiguate between person and agent. Since that time, Google’s Duplex6 and IBM’s Watson and Project Debator7 have made huge leaps in their capabilities to use syntax, semantics, and even linguistic behaviors. This leaves two characteristics still in play as a potential shibboleth:
1. User Profile – links to other accounts, biography, etc.
2. Network features – how distinct the person’s “network” is, i.e., where they work and others they connect to.
We will save the discussion of the various objects that should be tracked in a person’s profile for later, for now, we’ll just call this collection of objects a person’s information.
Since the DARPA challenge, a great deal of research and practical application has been put into place in order to disambiguate natural persons from agents as well as personal name disambiguation (once you know Joe Smith isn’t an agent, knowing Joe Smith is that Joe Smith versus another one)8. So much so, that there are several methodologies for extracting information about both people and organizations from given information such as URLs and email addresses9. We aren’t going to cover any of these for now – they will sit “on the back burner” as they say. For now, the easiest way to provide disambiguating information is to build out a personal dossier, so to speak, starting with that person’s current email address and what can be found via their public profiles.
The problem, therefore
**…**is how to
A. disambiguate a user so that we know Joe Smith is that Joe Smith and not some other Joe Smith; and
B. allow those disambiguating characteristics to be persisted between systems and digital identities so that as factoids change (name, address, email, etc.) the disambiguated person remains that person instead of some other person; and
C. ensure that Joe Smith isn’t an automated agent.
Disambiguating Organizational system user names
Disambiguating organizational system user names isn’t really that hard. It’s simply a matter of creating a coding system wherein naming options can be used. We’ve seen more than a few naming functions that ensure there are no duplicate names based on the default being first initial of first name and full last name. Then, when a duplicate is found, those functions
- add one more letter in the first name until it runs out,
- then add the middle initial (if there is one),
- then add a numerical sequence at the end of the name,
thus ensuring that there are no duplicate names within an organization’s user accounts.
That works fine for an organization, as the names themselves can be disambiguated. It doesn’t work fine in the larger context of a federated system, as names don’t provide enough disambiguating information in and of themselves (that, and you can’t rename document contributors).
Disambiguating names in a federated system
Within a federated system, users cannot be disambiguated by name. Period. Taking a cue from the US’ Library of Congress, what must be maintained for each person’s record is a federated authority identifier. The GRCSchema team, in agreement with OCLC, the ALA, the IFLA, and GODORT are contibutors to this cause. Each named Contributor within the Compliance as Code project will be added to the Authority List and will be tracked as such. The schema for this is found in NameAuthorityIdentifiers below. By doing this, we will be able to disambiguate each federated contributor from the others, and each will be given a unique and persistent ID.
Extracting personal information from disambiguating APIs
Various organizations have developed full-blown APIs for providing in-depth information about people, usually for marketing purposes, using their email addresses and domain names.
First and foremost, personal email addresses, such as those from Hotmail, Apple, Google, Yahoo, etc. cannot be used for extracting personal information. They just can’t. Any personal information extracted must be extracted from organizational email because the applications, such as ClearBit, FullContact, BigPicture, Powrbot, Crunchbase, ID.me, etc. all focus on business-to-business marketing, and as such, organizational e-mails. We will call these disambiguating APIs.
It is our postulation that there is enough information found within amalgamating information from a couple of the disambiguating APIs to put together a personal profile that is both disambiguating and persistent in nature without the need for a personal UUID for coherency.
A natural person can be disambiguated with persisting information when described in JSON-LD format using an amalgam of information found using disambiguating APIs.
Aligning the structure of Person across the Compliance as Code spectrum
There are over 20 organizations that have contributed schemas to the realm of Compliance as Code10. Of those, four of them specifically call out natural persons as either a contributor to compliance, or as a target of compliance. Those are StratML, OSCAL, STIX, Cybox, and ISO 19770-3. Below we explain the differences and relationships between those schemas and that of GRCSchema, which we present in the next section.
Of all the schemas that specifically call out natural persons as either contributors to compliance or targets of compliance, they seem to be split into two camps.
The name only camp
The first camp is the we don’t really care about people’s names camp, and these schemas are StratML, OSCAL, STIX, Cybox, ISO 19770-3, OASIS’ LegalXML, and VERIS. Their relationship to names is shown below with their schema’s version of the name object compared to our version of a name object. The ERD diagrams of each of these schemas as they match up to the GRCSchema’s version are in the footnotes.
| Schema | first_name | last_name | fullname or freeform_name |
|---|---|---|---|
| Cybox11 | name | ||
| ISO 19770-312 | trustDefinedByName | ||
| OASIS’ LegalXML13 | TLCPerson_showas | ||
| OSCAL14 | short-name | ||
| STIX15 | name | ||
| StratML16 | givenname | surname | |
| VERIS17 | name |
The full-blown person camp
The other camp is the one that the GRC Schema fully aligns with. This camp includes the FRBR, UCF, and Zotero. This camp breaks down the basics of the person from the potential arrays associated with the person (e-mail, name, phone number, and address) as shown in the ERDs below.
The federated Person schema can be found at GRCSChema.org HERE.
Analysis of existing Person schemas
Following is an analysis of the Person schemas that exist in the various schemas we’ve examined.
StratML
StratML calls a natural person a submitter. Their data structure for submitter is relegated to a simple table for name, phone number, and email address, as shown below.
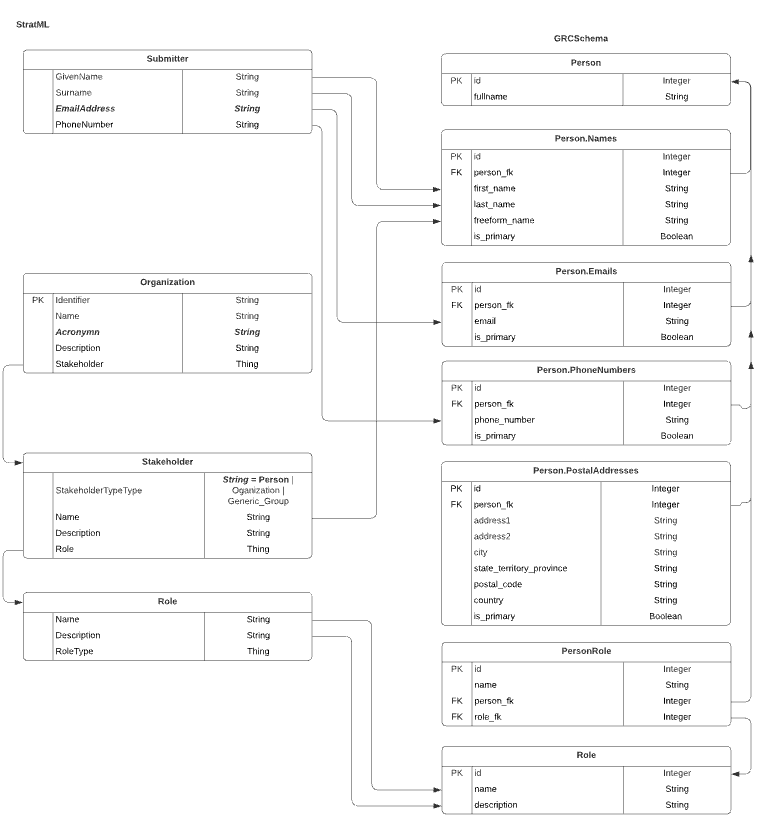
StratML has both a first name (GivenName) and last name (Surname), so this is easy to concatenate into a full name (fullname) in GRCSchema.
OSCAL
OSCAL refers to a natural person as a party. In addition to name, phone, and email, they also include address, as shown below.
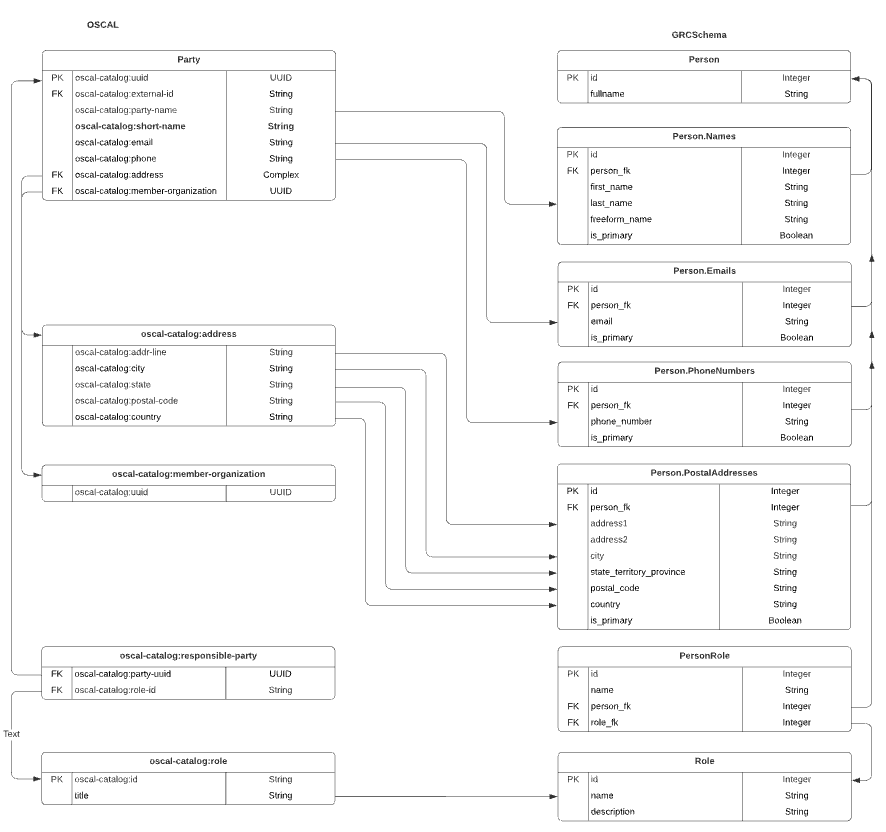
The problem with OSCAL, as you’ll see with some of the others, is that they only have a fully concatenated name. There doesn’t seem to be a way to discern first name and last name, let alone a person’s prefix, middle name, and suffix.
STIX
STIX’s schema for a threat actor is very minimal but includes one major distinction – type. STIX’s threat actor can be a natural person, agent, group, organization, or even nature. Hence type is used to disambiguate between the various forms the threat actor can take.
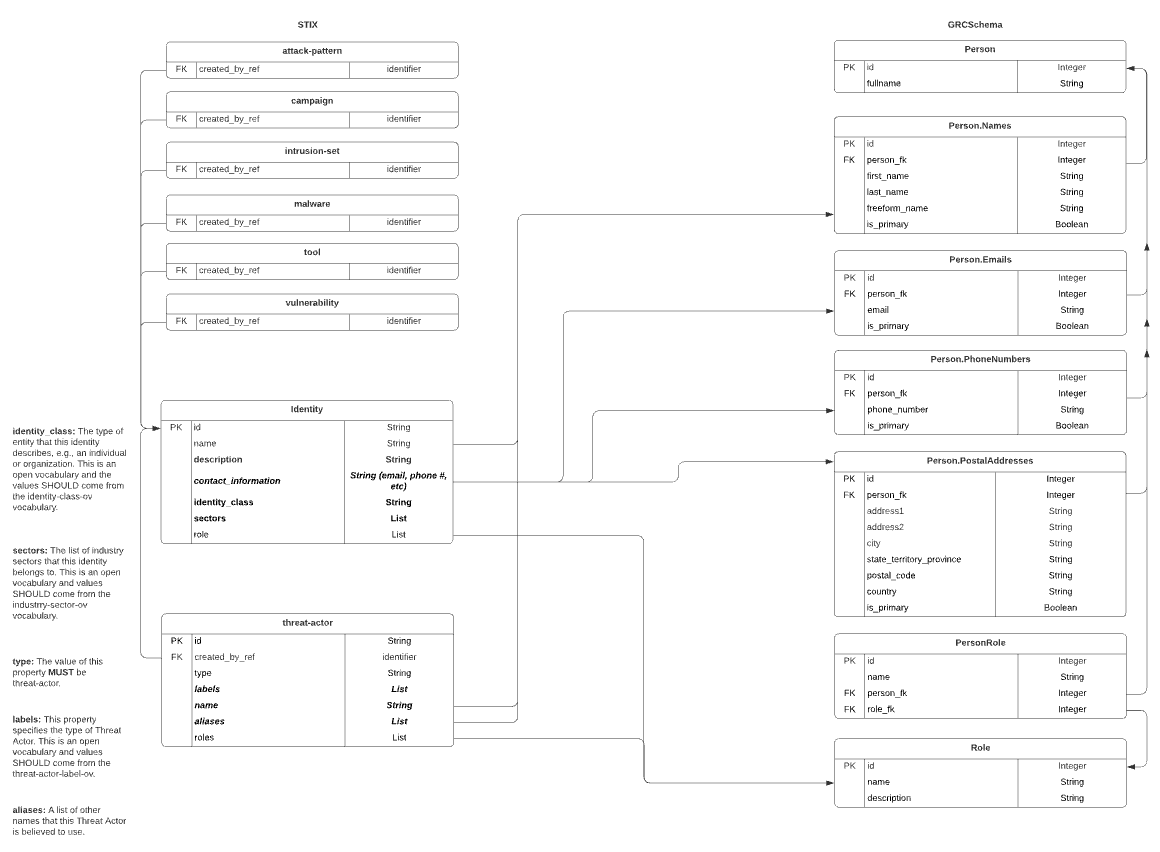
STIX suffers the same single-field naming problem. Because names can’t truly be discerned between first and last name, they must be mapped into GRCSchema’s freeform_name object.
Cybox
Cybox, incorporated into a great many of OASIS’ schemas, adds the addition of role (which we will cover in its own JSON Thing, later) to its contributor.
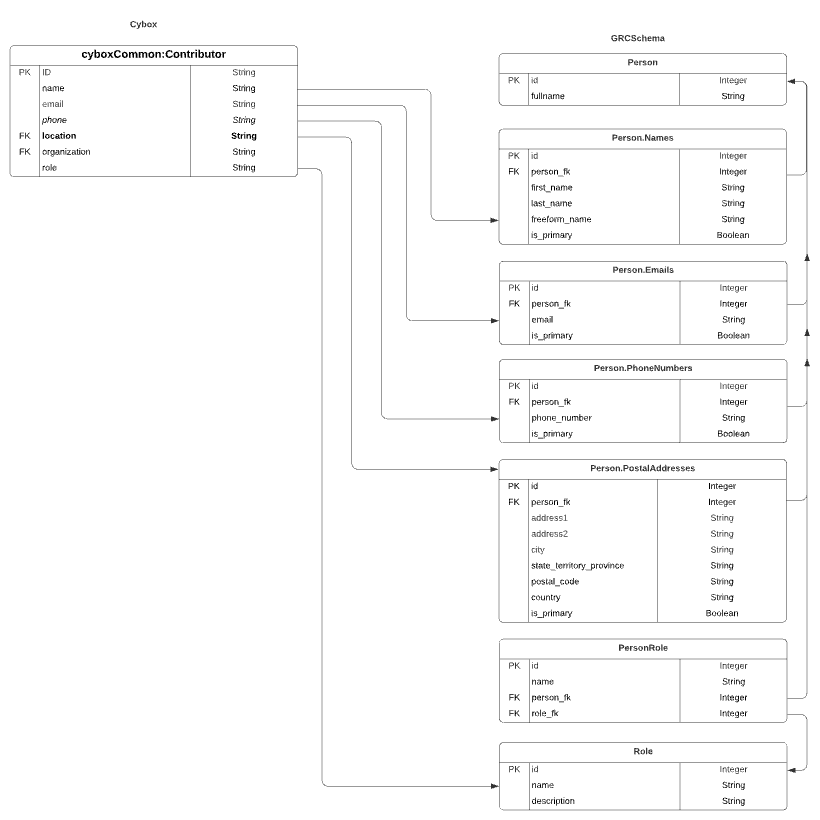
Cybox suffers the same single-field naming problem. Because names can’t truly be discerned between first and last name, they must be mapped into GRCSchema’s freeform_name object.
ISO 19770-3
While ISO 19770-3 doesn’t come out and have a full-fledged person identity, they do deal with trustdefinedbyname.

ISO 19770-3 suffers the same single-field naming problem. Because names can’t truly be discerned between first and last name, they must be mapped into GRCSchema’s freeform_name object.
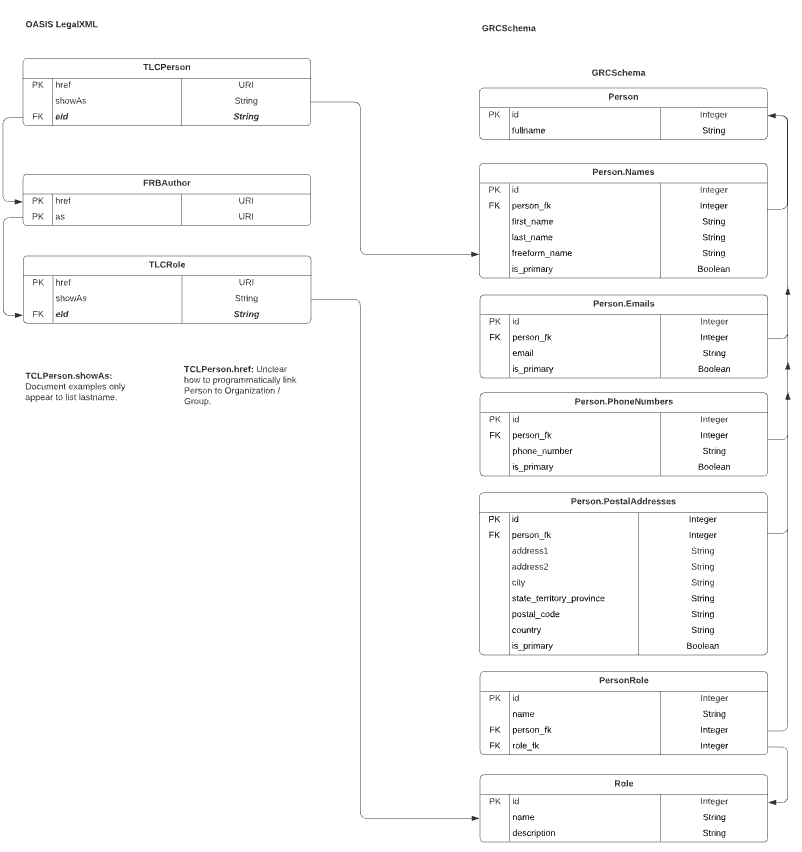
OASIS LegalXML
OASIS’ LegalXML doesn’t deal with Person’s names very well. It seems, through examination of their documentation and schema, that their TLCPerson and FRBAuthor example only appear to list last names. Therefore, we’ve linked their idea of a person to the GRCSchema’s freeform_name object.
Zotero, RDA, FRBR
Zotero, RDA, and FRBR, as well as any of the other bibliography and library catalog schemas, have a full-blown person schema that matches the Person schema found in GRCSchema, so we won’t show their very detailed schema next to the GRCSchema, as the two are 99% identical.
Footnotes
- You’d think there was a great deal of research, or even “google-able” information on how to do this. Nope. As of this writing, Google has 88,000+ articles on digital disambiguation, but most of them are about how Netflix and others are trying to do it through data profiling. We have a few good research documents you can find in our online research library HERE. ↩
- (“FOAF Vocabulary Specification” n.d.) ↩
- https://compliancedictionary.com/term/8166 ↩
- A shibboleth is a way the old Isrealite army used to detect imposters from their own by manner of dialect. The term was featured in a great episode of the television show West Wing wherein the President had to determine if a person was trying to lie about something important. You can see that part of the episode HERE. ↩
- (Subrahmanian et al. 2016) ↩
- (“Google Demos Duplex, Its AI That Sounds Exactly like a Very Weird, Nice Human” n.d.) ↩
- (Fan 2019) ↩
- (Vu et al. 2007) ↩
- (Delgado et al. 2018) ↩
- https://short.grcschema.org/CAC001 ↩
- https://short.grcschema.org/art-Cybox-Person ↩
- https://short.grcschema.org/art-ISO19770-3-Person ↩
- https://short.grcschema.org/art-Oasis_LegalXML-Person ↩
- https://short.grcschema.org/art-STIX-Person ↩
- https://short.grcschema.org/art-STIX-Person ↩
- https://short.grcschema.org/art-StratML-Person ↩
- https://short.grcschema.org/art-VERIS-Person ↩